As you are probably aware, the Ping command is one of the most widely used diagnostics tool when troubleshooting communication issues on Ethernet networks. I would accredit this popularity to the fact that everyone knows how to use the command, it's extremely simple to execute, and the results are not really open to interpretation (i.e. it either works or it doesn’t); or are they?
When troubleshooting communication issues, the most common line we hear when something isn’t working is “but I can ping it” as if this alone should serve as definitive proof that everything is working as expected and the communications server is choosing to not communicate.
Continuing our Tech Support Corner blog series, this blog post covers some common misconceptions about the Ping command, particularly how it can be used efficiently, and when it may not be the best tool for the task, as well as, better alternatives to Ping that actually provide actionable data.
When troubleshooting communication issues, the most common line we hear when something isn’t working is “but I can ping it” as if this alone should serve as definitive proof that everything is working as expected and the communication server/solution being used is simply choosing to not communicate. Here I want to address some common misconceptions about the Ping command, particularly how it can be used efficiently, and when it may not be the best tool for the task.
What is the Ping command?
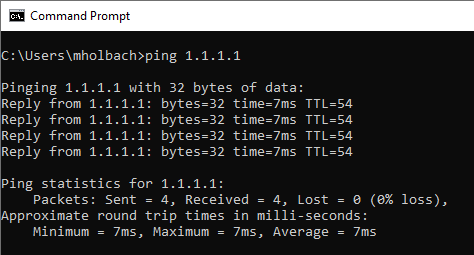
What happens when you type ping 1.1.1.1 in a command prompt?
Ping is meant to tell a user whether a host is reachable on an IP network, and does so by sending out an ICMP (Internet Control Message Protocol) echo request, which the remote host (the IP Address we are pinging) will echo when received.
While this is undoubtedly useful, the Ping command is also extremely limited in what it tells us because ICMP sits on top of the IP protocol (after all, it IS the Internet Control Message Protocol) and does not need a transmission protocol like TCP or UDP.
Why is this significant?
Well, where the Internet Protocol describes communications between hosts, Transmission Protocols (like TCP or UDP) describe the communications between processes running on those hosts. With no transmission layer, a Ping command will NEVER be able to give us information on whether the remote host:
- is listening for connections
- has an open port
- will accept a connection from our process
- is even the right host we are wanting to communicate with
A Ping command will only tell us that there is a host responding to the echo request at the specified IP address.
So, the shortcomings of the Ping command can be summarized in that the command simply does not give us enough information to make an intelligent conclusion of why a controller or network node is not communicating. So, what are some alternatives to the Ping command that are worth considering in such situations?
What is the Tracert command?
The Tracert command largely serves the same purpose as the Ping command and should only be used to determine if there is something out there responding at the IP Address specified, and nothing more.
If you are pinging a device on the same subnet, then Tracert and Ping will do the exact same thing. The power of Tracert comes when pinging hosts that are NOT on the same subnet or network, as it will not only show whether the end device is responding but will also show the routing path to get to that remote host.
If the Tracert fails at any specific point in the path, it is easy to identify the specific place where the communications are breaking down.
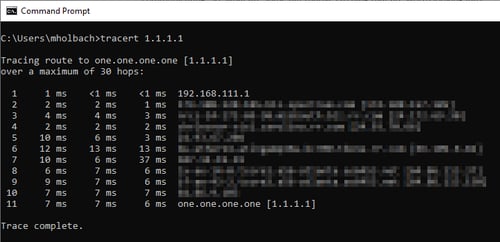
Tracert does this by sending out the same ICMP Echo request that ping does, but it uses the "Time To Live" field to control how far the message can jump. The first packet is sent with a TTL of 1, which the first jump in the path will decrease to 0 and respond with a “Time to live exceeded in transit”, which helps our machine to now know the IP address of the first jump in the routing path.
The second echo request is then sent with a TTL of 2, so that the message can make it to the second hop in the path before timing out. Then comes a TTL of 3, TTL of 4, and so on, until we get an Echo response, and we know the ‘ping’ packet has made it to the destination node we were attempting to reach.
Just as with a ping, the Tracert results tell us nothing about whether there is an application/firmware/communication module running on the remote host that is capable of communicating with us – only that the remote host supports IP and is reachable.
So we've now established that Ping and Tracert commands are essentially the same with respect to how useful they are in troubleshooting communication issues in many circumstance. What else can we try?
What is the Portqry Utility?
If the Ping command doesn’t give us any actionable data, and the Tracert command doesn’t give us any actionable data, how CAN we get something we can use to determine if a device is listening for a connection and what the communication issues might be? That question brings us to the PortQryUI - a downloadable utility from Microsoft - to download PortQryUI, click here.
While it does not come pre-installed with Windows, PortQryUI is a very lightweight utility that can be used to not only identify if a host is reachable, but whether a process running on that host is reachable and/or willing to accept connections.
Knowing that 1.1.1.1 is a DNS server, as we've previously established, let's run Portqry against the DNS port of 53.
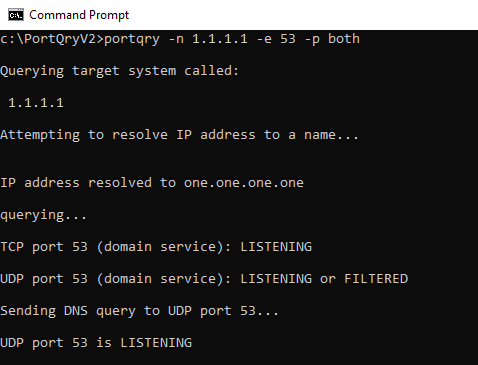
We can see that, first, Portqry attempts to resolve the IP address to a DNS hostname (which it does successfully here - “one.one.one.one”), before querying the port using both TCP and UDP and, since the utility knows the 53 is the DNS port, it sends a DNS query to the port as well.
There are three possible results to a Portqry:
- Listening – the utility received a positive response from the port
- Not Listening – the utility received a response from the port telling us to go away
- Filtered – the utility did not receive any response from the port, positive or negative
Let's now try this with a local Modbus PLC in the lab here, which we know is expecting to see connection requests over port 502 (the default Modbus port).
This time I scan a range of ports 502-503 and still request that both TCP and UDP be checked.
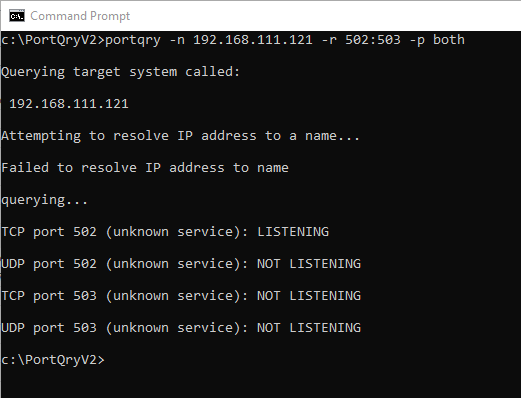
The results are not surprising; the host name resolution fails, since it is just a PLC (while it isn't out of the realm of possibility for a PLC to be assigned a DNS name, most are not), and the query results do indeed show that there is a process listening on port 502 for incoming TCP connections.
Now, obviously, we're not having any communications issues with the Modbus PLC in our lab. However, you can now imagine how useful the Portqry utility can be with an unresponsive device when it responds with "Not Listening" or "Filtered" for the port and transport that we would expect a positive response from under normal circumstances of good communications.
But what else can we do if we are getting a positive response from Portqry but still have unsuccessful communications?
What is Netstat?
After the first revision of this blog post was published, a commenter kindly pointed out (Thank you Dan!) that I had made a serious omission – one that I am embarrassed to have made – in leaving out any mention of the Netstat command. While the Netstat command does not provide information of the ability of a remote device to accept a connection, or whether the remote host is reachable on the network, it is an invaluable resource when looking at the socket states on the local machine.
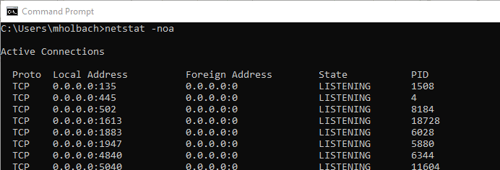
Running a simple netstat enumerates the local socket information, showing the local and remote addresses, the socket state, and the process ID associated with that topic (particularly useful when wanting to track down which application was using a port). When troubleshooting connection issues to a PLC, the socket state would be the most useful column, as it gives insight into where along the connection sequence the issue is occurring. When filtered (using FIND) the Netstat list can easily be filtered for any keyword; including IP addresses and ports:
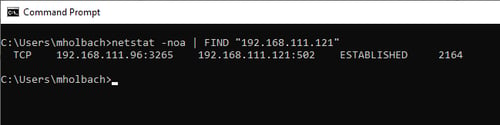
When interpreting the Socket state it is important to have – at least in general terms – an understanding of the TCP state diagram to see where in the connection sequence the error is occurring. Undoubtedly this is useful, and only scratches the surface of what netstat is capable of, and I highly recommend running a netstat /? to see all options available.
What is Wireshark?
While the focus of this article is meant to be on lightweight diagnostic tools that can be used as an alternative to a simple Ping command to quickly troubleshoot basic connectivity issues, I could not – in good faith – discuss how to troubleshoot ethernet connectivity issues and not mention Wireshark.
If all else fails, and the tools above show that everything should be working when they’re not, Wireshark is our go-to diagnostic tool. Wireshark will capture all traffic on a network card, and will show us what exactly is going on between the target device and our machine.
For a more information about using Wireshark, visit our Tech Support Corner post on using Wireshark and you can also take a look at our Introduction to Wireshark Network Analysis whitepaper, available in our knowledge base.
So, in conclusion, while the Ping command certainly has its place as a very basic troubleshooting tool, it should NOT be mistaken for a tool that does it all, nor should a successful Ping be treated as anything more than it is – a simple confirmation that there is an IP host out there that is responding to our ICMP requests.
Don't forget to subscribe to our blog to get more useful tech support tips like this one and for the latest Software Toolbox product news every week.