I think it's safe to say that when we're discussing databases in the context of industrial process control, SQL Server is where most of our brains tend to jump. The proliferation of SQL (and other traditional relational databases) across most, if not all, industries for process control applications cannot be denied. But SQL (and others) do certainly have some limitations.
This blog post (based on an article by partner company, inray Industriesoftware GmbH) discusses how MongoDB, a non-relational database (i.e. NoSQL database) are fundamentally different from the SQL Servers of the world and how MongoDB can be a good alternative to relational databases for some applications.
So before we discuss how MongoDB does things differently from relational databases, let's first discuss what MongoDB is, since I'm sure there are plenty of readers who may have never heard of it. MongoDB is a database that relies on a non-relational document model. As such, it can be referred to as a NoSQL database (NoSQL = Not-only-SQL).
![]() As such, MongoDB differs fundamentally from conventional relational databases such as Microsoft SQL Server, Oracle, MySQL or the multitude of others out there. The roots of the name "MongoDB" come from the English word “humongous”, another word for massive or gigantic. Released in 2009, MongoDB was the brainchild of founder and developer Eliot Horowitz, who was Chief Technology Officer and on the Board of Directors of MongoDB Inc. until 2020 and is still active as a technical consultant.
As such, MongoDB differs fundamentally from conventional relational databases such as Microsoft SQL Server, Oracle, MySQL or the multitude of others out there. The roots of the name "MongoDB" come from the English word “humongous”, another word for massive or gigantic. Released in 2009, MongoDB was the brainchild of founder and developer Eliot Horowitz, who was Chief Technology Officer and on the Board of Directors of MongoDB Inc. until 2020 and is still active as a technical consultant.
How Relational vs. Non-Relational Databases Differ
Conceptualizing the differences between the document-oriented NoSQL database model of MongoDB and a conventional SQL database is best explained in the following example at a plastics manufacturer.
How Data is Stored in a Relational Database at a Plastics Manufacturer
In the business office for a plastics manufacturer, a relational database (i.e. SQL or similar) is used for customer management. Their database stores the customer data (in similar fashion to an Excel table consisting of rows and columns). Let’s first look at a small part of this database, the contact information for the customer. It could start with a simple table that contains one row for each customer. This row has a unique customer ID number, a first and last name, email address, phone number and the company's address. Simple, right? However, what if we need to add a second phone number for the same customer?
Simple, right? However, what if we need to add a second phone number for the same customer?
For a work number and a mobile number or even an emergency contact number, we could simply add more columns. However, the same need could arise with multiple addresses, for example if a client wants a sample sent to their home office or they have a different mailing address vs. shipping address, etc.
Also previous addresses or information for a preferred special color for the plastic parts a customer purchases could be information you might also need to store. Each time, you're simply adding more columns for all of the customer’s contact information.
Certainly this works but eventually you will end up with a bloated, mostly empty and inefficient table since many of those fields that were required for a subset of your customers remain unused for many other customers and simply take up space in the database.
So what is the alternative to the single, inefficient table model in a relational database? Instead, new spreadsheets could be created in the Excel model if additional pieces of data are required for a customer or customers. So, for instance, below we have a new separate sheet for telephone numbers, which contains only one telephone number in each row, which refers to the customer ID and is marked with a label like “Private”, “Work” or “Mobile”. Another sheet can be created in this way for addresses, another for quotations and so on.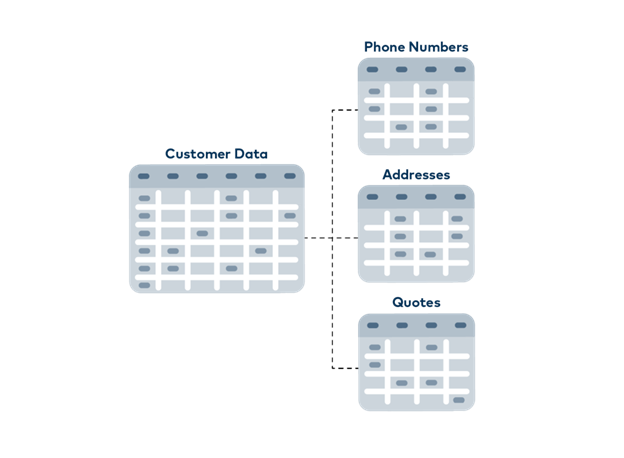 The plastic manufacturer could create a multitude of sheets just to look at a single customer and here no thought has even been given to order history or invoice filing. You can guess how quickly working in this rigid schema can get out of control, though. However, in a traditional relational database, this is how developers work with data in real applications.
The plastic manufacturer could create a multitude of sheets just to look at a single customer and here no thought has even been given to order history or invoice filing. You can guess how quickly working in this rigid schema can get out of control, though. However, in a traditional relational database, this is how developers work with data in real applications.
Disadvantages to Relational Database Data Handling
So the data for a single "thing", like a customer, is often spread over dozens of tables and sheets in that model. This significantly increases the complexity of the application and leads to some disadvantages, including:
- Increased Complexity - For users who maintain the application, it is difficult to understand the complex and multi-layered structures.
- Difficulty Adding New Features - Adding features is more difficult because, for example, with cross-references there are more tables and sheets to consider.
- Inefficient Data Retrieval - Retrieving data from so many places is inefficient and applications need complex programming codes to deal with it.
Now consider how this example would play out in a world without computers - sales representatives would have to retrieve names from one file folder, phone numbers from another and addresses from a third folder. While we don't live in that world and computers would dull the pain of such a scenario slightly, you can imagine how complicated, error-prone and slow that would be. It's not the best use of computing resources working with such an inefficient model.
How MongoDB Addresses the Disadvantages of Relational Databases
MongoDB follows a completely different “schema-free” approach. Data is stored in so-called “documents”. Just like physical customer files in a hanging file, a "document" can contain two addresses, three phone numbers and other information, such as an individual training video. It can be stored right next to another customer document that contains only a phone number, an address and no orders yet. These documents are not limited to having the same number of column documents or data fields.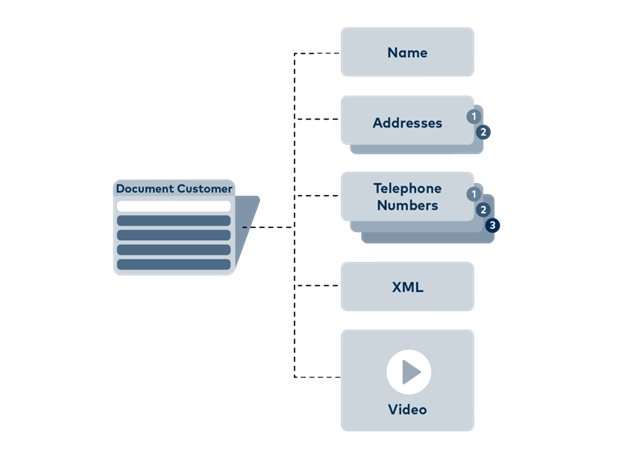 MongoDB groups several documents into “collections”, of which the database can contain several. IT can process the data structured in this way more efficiently and, of course, these documents are also much easier for people to read.
MongoDB groups several documents into “collections”, of which the database can contain several. IT can process the data structured in this way more efficiently and, of course, these documents are also much easier for people to read.
This model of data storage is incredibly beneficial for developers since they no longer have to adapt their applications to the requirements of the database. With MongoDB, applications can store data in a natural and convenient way. This also means that adding new data is possible without worrying that a simple change could cause existing database records to become unreadable.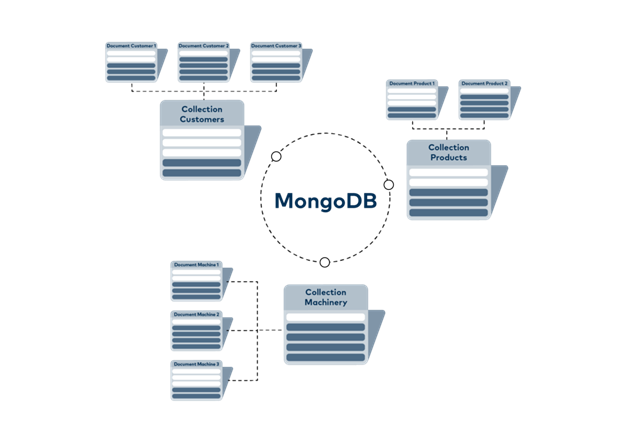 Aside from this document model, MongoDB is fundamentally different from traditional databases because its functionality allows MongoDB to leverage multiple servers for data storage. This enables MongoDB as a distributed database and allowing for fault tolerance, scalability, and data availability features that developers would otherwise have to create themselves and, as such, mitigates risk and increased effort.
Aside from this document model, MongoDB is fundamentally different from traditional databases because its functionality allows MongoDB to leverage multiple servers for data storage. This enables MongoDB as a distributed database and allowing for fault tolerance, scalability, and data availability features that developers would otherwise have to create themselves and, as such, mitigates risk and increased effort.
Let's highlight these differences (advantages) further:
- Better Fault Tolerance - To ensure fault tolerance in the work, redundant copies of the same data are kept on different servers. A failure of a single server does not affect the application.
- Greater Scalability - MongoDB scales seamlessly to multiple servers to store and process data. So data volume and performance requirements increase. You can simply add more servers instead of upgrading expensive mainframes. This is also ideal for cloud environments where the load is distributed across many computers.
- Geographically Distributed High Availability - Data is available locally near users around the world for quick access.
The combination of the MongoDB document model and the distributed system components gives MongoDB an advantage over relational databases. In addition, the “Mongo” company also provides management tools that allow database operators to oversee the configuration, monitoring, backup, recovery and updating of MongoDB clusters. This is essential in order for MongoDB to be well-suited for the most demanding use cases and for organizations with stringent SLA (Service Level Agreement) and operational requirements (which are common with industrial process control applications).
MongoDB as a Cloud Solution and SaaS
With the "cloud" becoming an increasingly utilized concept for sharing industrial process data and data analysis, it's important to be aware that MongoDB was developed for the cloud and has been widely used there for some time.

Additionally, more and more users are also interested in creating their applications with components that are offered as a “service”. To that end, MongoDB is also available as “MongoDB Atlas” which has been released as a Software as a Service (SaaS) option.
Atlas allows MongoDB to be used as a service without having to worry about managing the database. MongoDB Atlas is available on the leading cloud platforms Amazon Web Services (AWS), Microsoft Azure and the Google Cloud Platform.
This provides the flexibility to choose a public cloud provider without being locked in to a specific vendor and without having to rewrite code for a specific vendor. These innovations are driving more and more companies to incorporate the MongoDB platform.
While MongoDB was developed as an open source project by the community and is now also used extensively in the industrial environment, their paid options are also widely utilized for business-critical applications that need fully managed failover and complex recovery options. However, the community server version available free of charge at www.mongodb.com is an excellent way to enter the NoSQL world with this database (for steps on installing MongoDB and getting started, click here).
We hope this blog post has given you some insights into how MongoDB might be a good fit for your projects. If you're interested in how to log your process data to MongoDB or integrate data from MongoDB with your process, the OPC Router MongoDB Plug-in can access the data in MongoDB in read and write modes and supports handling of the replication capabilities in MongoDB. For more details, click here. You can try OPC Router for logging/reading from MongoDB with the free trial available here.